2025. 8. 29. 20:49ㆍ스프링
N+1 문제란?
N+1 문제는 2개 이상의 JOIN 된 테이블에서 연관된 데이터를 조회할 때 하나의 쿼리로 조회가 가능한 상황이지만
JPA 구현체는 1개 + N개의 쿼리로 조회하는 문제를 말합니다.
N+1 확인하기
예제 엔티티 구조
@Entity
public class MeetingEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String meetingName;
@OneToMany(mappedBy = "meeting")
private List<ParticipantEntity> participants = new ArrayList<>();
}
@Entity
public class ParticipantEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "meeting_id")
private MeetingEntity meeting;
}
예제 테스트
@SpringBootTest
class Nplus1DemoApplicationTests {
@Autowired
private MeetingRepository meetingRepository;
@Test
@Transactional
void nPlus1Test() {
List<MeetingEntity> meetingEntities = meetingRepository.findAll();
System.out.println("Meeting Cnt : " + meetingEntities.size());
for (MeetingEntity meeting : meetingEntities) {
List<ParticipantEntity> participants = meeting.getParticipants();
int size = participants.size();
System.out.println("=================================");
}
}
}
실행 결과 로그

meetingRepository.findAll() 실행 시 위처럼 SQL이 1번 실행됩니다.
이후 meetingEntity의 participant의 메서드에 접근 시 모임의 개수만큼 SQL이 실행됩니다.
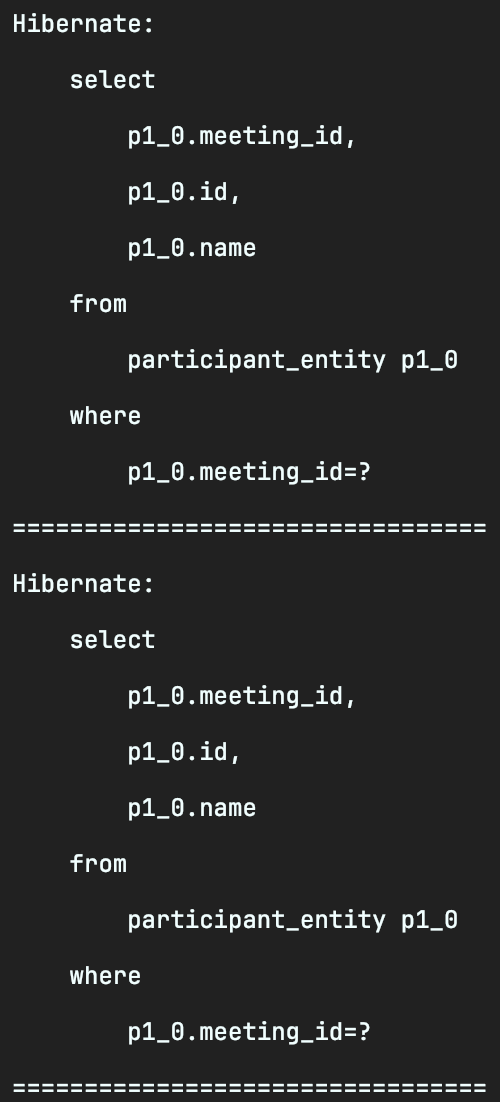
이 처럼 JOIN으로 모임의 참가자까지 한 번에 조회할 수 있음에도
모임 조회(1) + 모임의 개수만큼 조회(N)만큼 SQL이 실행되는 걸 확인할 수 있습니다.
(연관관계의 주인이 아닌 MeetingEntity는 @OneToMany로 되어있기 때문에 fetch 전략이 기본값인 LAZY이기 때문입니다.)
(fetch 전략을 EAGER로 한다면 처음에 MeetingEntity를 조회할 때 바로 N+1문제가 발생합니다.)
예제에서는 모임이 2개였지만, 데이터가 쌓여 모임이 많아진다면 성능문제가 발생합니다.
fetch join을 통한 문제 해결
JPQL에서 join fetch 구문을 사용해서 연관 엔티티를 한 번에 함께 조회해 문제를 해결해 보겠습니다.
public interface MeetingRepository extends JpaRepository<MeetingEntity, Long> {
@Query("select m from MeetingEntity m join fetch m.participants")
List<MeetingEntity> findAllWithParticipant();
}
위처럼 @Query 어노테이션을 사용해서 join fetch 구문을 만들어주고 해당 메서드를 사용하면 됩니다.

로그를 보면 join을 사용해서 한 번에 조회해 추가로 쿼리가 발생하지 않는 것을 확인할 수 있습니다.
fetch join을 사용할 때 문제점
1. 데이터 누락
fetch join 사용 시에는 데이터 누락 문제가 발생할 수 있습니다.
OneToMany에서 One에는 데이터가 있지만, Many의 데이터가 없는 경우가 문제가 됩니다.
예를 들어 모임(One)은 있지만 모임(Many)에 참가자가 없는 경우 One도 함께 조회되지 않는 문제가 발생합니다.
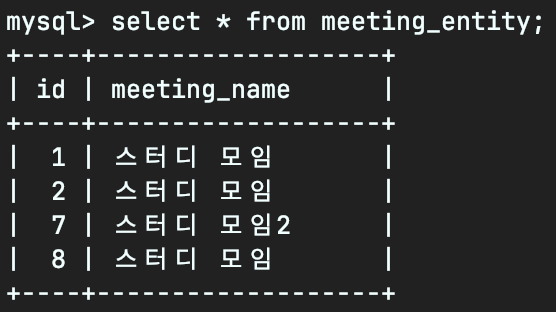
이렇게 4개의 모임 데이터가 있지만, fetch join으로 조회 시에

하나의 모임에는 참가자가 없으므로 3개의 모임만 조회되는 경우가 있을 수 있습니다.
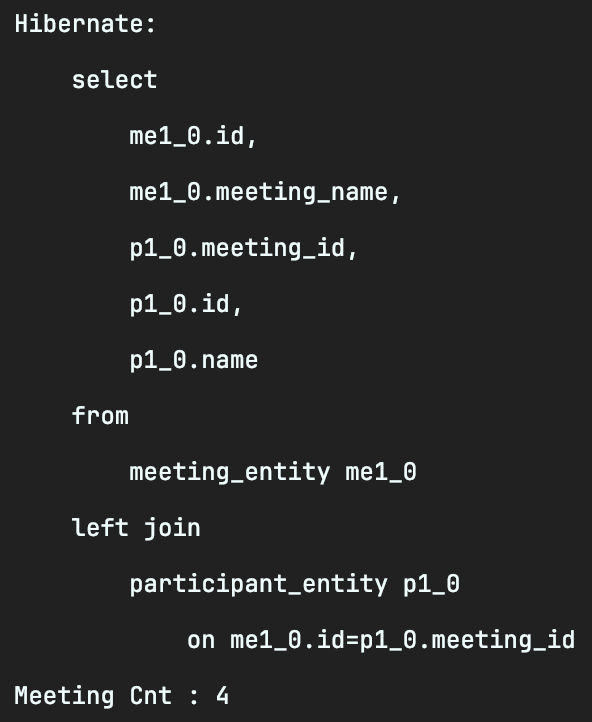
이는 inner join이 되어서 발생하는 문제이므로 left join fetch를 사용하면 의도한 대로 데이터를 가져오는 걸 확인할 수 있습니다.
2. 다중 OneToMany fetch join 문제
실제 DB 설계 시에는 하나의 테이블에 여러 개의 연관관계를 가지는 경우가 많습니다.
그렇게 된다면 OneToMany관계가 하나가 아니라 여러 개가 되는데 이때 fetch join을 사용한다면 문제가 발생할 수 있습니다.
예시를 위해서 모임에 일정을 추가하겠습니다.
@Entity
public class MeetingEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String meetingName;
@OneToMany(mappedBy = "meeting")
private List<ParticipantEntity> participants = new ArrayList<>();
@OneToMany(mappedBy = "meeting")
private List<ScheduleEntity> schedules = new ArrayList<>();
}
@Entity
public class ScheduleEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "meeting_id")
private MeetingEntity meeting;
}
ScheduleEntity를 추가하고 fetch join을 아래와 같이 추가해 테스트해 보겠습니다.
@Query("select m from MeetingEntity m " +
"left join fetch m.participants " +
"left join fetch m.schedules")
List<MeetingEntity> findAllWithParticipantsAndSchedules();
테스트를 진행하면 MultipleBagFetchException 에러가 발생하는 것을 확인할 수 있습니다.
왜 이런 에러가 발생하는지 알아보겠습니다.
예를 들어서 모임에 3명의 참가자, 2개의 일정이 있다고 하면 아래와 같은 결과가 나올 것입니다.
| meetind_id | meeting_name | participant_id | schedule_id |
| 1 | "스터디" | p1 | s1 |
| 1 | "스터디" | p1 | s2 |
| 1 | "스터디" | p2 | s1 |
| 1 | "스터디" | p2 | s2 |
| 1 | "스터디" | p3 | s1 |
| 1 | "스터디" | p3 | s2 |
결과를 보면 곱연산이 된 Cartesian Product가 넘어오는 걸 확인할 수 있습니다.
Hibernate는 이러한 SQL 결과를 Java객체로 변환시키는 과정에서 중복을 제거하는데, 중복을 제거하는 조건이 까다로워서 2개 이상의 OneToMany fetch를 할 경우 에러를 던져서 강제로 막고 있습니다.
해결방법 1. List대신 Set사용
중복을 제거하기 위해서 List대신 Set을 사용하는 방법입니다.
@Entity
public class MeetingEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String meetingName;
@OneToMany(mappedBy = "meeting")
private Set<ParticipantEntity> participants = new HashSet<>();
@OneToMany(mappedBy = "meeting")
private Set<ScheduleEntity> schedules = new HashSet<>();
}
Set으로 적용했을 때는 에러가 발생하지 않고 정상적으로 조회가 됩니다.
간단하게 문제를 해결할 수 있다는 장점이 있지만, Set은 순서를 보장하지 않으므로 순서가 중요한 경우는 사용하지 않는 것이
좋습니다. 추가로, 올바른 중복제거를 위해서 정확한 id 기반의 hashCode(), equals() 구현이 필요할 수 있습니다.
해결방법 2. 한쪽만 fetch 나머지는 In절 사용 (@BatchSize)
우선, 아래처럼 한쪽에만 fetch join을 사용하고 나머지에는 단순히 left join을 사용합니다.
@Query("select m from MeetingEntity m "
+ "left join fetch m.participants "
+ "left join m.schedules")
하지만 이 경우에는 join fetch를 걸지 않은 쪽에는 다시 1+N 문제가 발생하기 때문에 @BatchSize 어노테이션을 활용해 In절로 처리가 되도록 설정합니다.
(@BatchSize: Lazy로딩 시 한 번에 여러 건의 데이터 FK로 묶어서 IN절로 가져옴.)
@Entity
public class MeetingEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String meetingName;
@OneToMany(mappedBy = "meeting")
private List<ParticipantEntity> participants = new ArrayList<>();
@OneToMany(mappedBy = "meeting")
@BatchSize(size = 20) // <- 한 번에 최대 20건씩 모아서 조회
private List<ScheduleEntity> schedules = new ArrayList<>();
}
이렇게 나머지 OneToMany는 해당 proxy에 접근 시 In절로 조회를 합니다.
결론
필요하지 않은 상황에서는 fetch join을 사용하지 않는 것이 성능적으로 더 뛰어나므로, 필요에 따라서 LAZY 전략과 fetch join을 적절히 사용해 N+1 문제를 해결하는 것이 서비스의 성능 개선에 도움이 될 것 같습니다.
'스프링' 카테고리의 다른 글
| [JPA] Hibernate @SoftDelete (0) | 2025.09.05 |
|---|---|
| [JPA] Jackson 직렬화 문제 - 해결 방법 (3) | 2025.08.22 |
| [JPA] Jackson 직렬화 문제 - Hibernate Proxy 객체 (0) | 2025.08.22 |
| [JPA] Jackson 직렬화 문제 - LAZY vs EAGER (1) | 2025.08.21 |
| Spring AOP 알아보기 (1) | 2025.06.20 |